

When it comes to training AI models, data labeling plays a crucial role.
There is a reason why the data labeling market is now valued at more than USD 2 billion.
However, if you are unfamiliar with its workings or use cases, or if you confuse it with data annotation, you are not alone!
In this blog, I will define and explain data labeling in the simplest terms, along with its working and advantages.
Just to give you a heads up, HiredSupport offers data labeling services starting from just USD 7, but that’s a story for later.
Buckle up, and let’s get started!
How Does Data Labeling Work?
The first thing that comes to mind when I think of data labeling is the process of assigning labels to each object in raw data.
As the name suggests, labeling helps machine learning models understand what the data represents.
However, there’s more to the data labeling process than just assigning tags.
For a supervised machine learning (ML) model, learning from a proper training set is the key to efficient output. And that’s where data labeling comes into play.
Note: I know that understanding how data labeling words can be confusing. So, I will keep things simple from here onwards.
Steps Involved in the Data Labeling Process
Here are the steps that form the basis of this process:
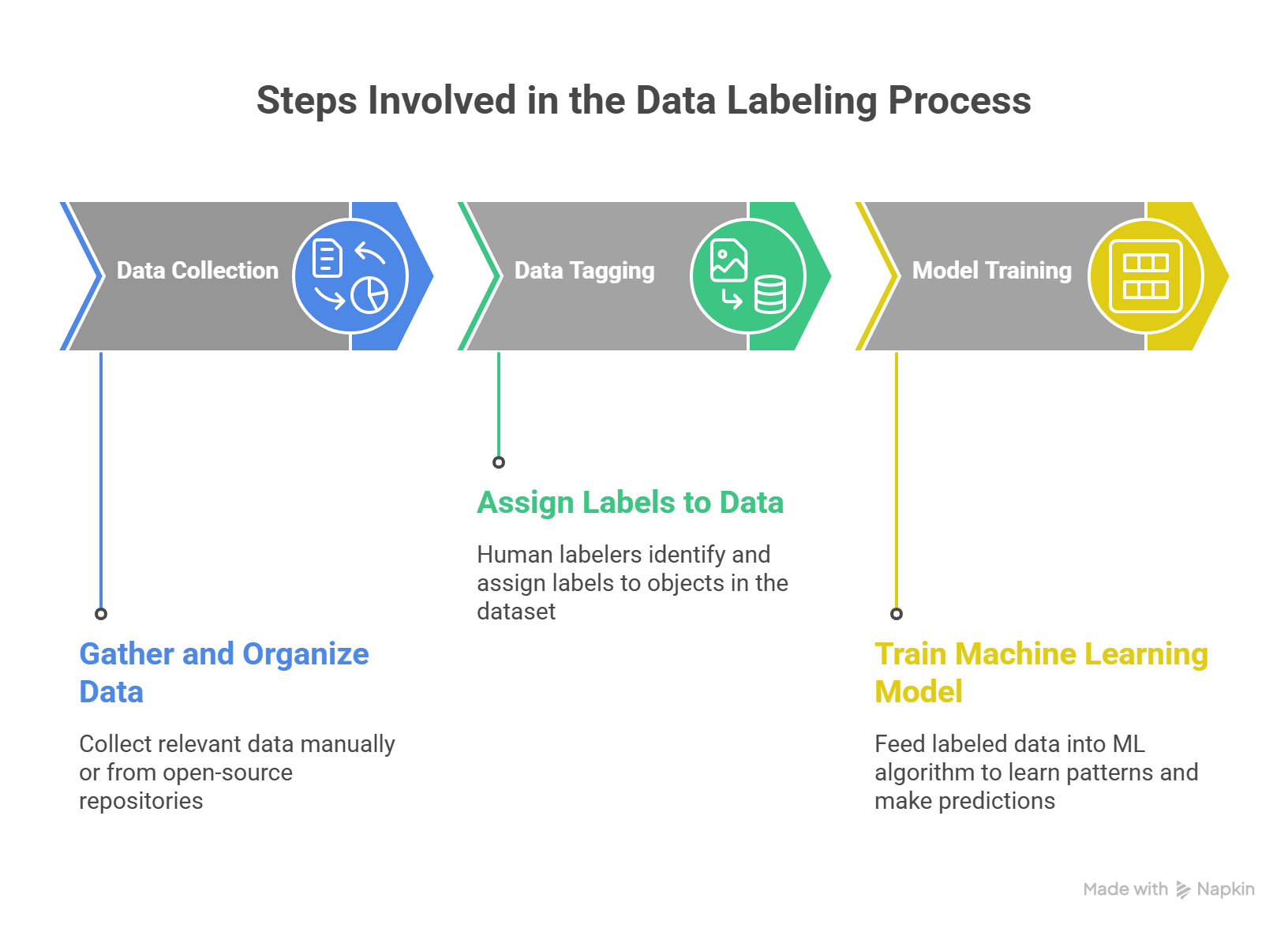
Data Collection
The first step is to collect and organize the relevant data. Here you have two options: either collect the data manually or choose an open-source dataset from an online repository.
The approach depends entirely on your AI model’s requirements.
Data Tagging
To ensure the training dataset is actually useful for the ML model, accurate data tagging is crucial.
Data tagging involves assigning labels to each object in the dataset.
In this step, human labelers identify specific characteristics, such as whether an image contains a dog, cat, human, or background.
The final output of this step is a labeled dataset that can be used for model training.
Model Training
Once the dataset is labeled, the next step is model training.
Here, the labeled data is fed into the machine learning algorithm. After training, the model learns to recognize patterns and can make accurate predictions when exposed to new, unseen data.
This is how a supervised machine learning process works…and why labeled datasets are so important.
What Makes Data Labeling Important [Key Benefits it Offers]
If you are still unaware of the significance of data labeling, you are in the right place.
Let’s discuss the key benefits of this process and why it’s the key to accurately train an ML model:
1. Ensures High Quality
When it comes to ensuring the high quality of your machine learning models, efficient data labeling is a very important factor.
2. Provides Optimal Output
The output of your ML-based applications is directly related to the labeled dataset. Using the right method to label the training dataset means more accurate results.
3. Generates Useful Analytics
Accurate data labeling provides you with insights and analytics that can help you make the right decisions for your business.
What are the Different Methods of Data Labeling?
Now that you understand what data labeling means and why it’s important, it’s worth noting that there isn’t just one way to label data.
Depending on your dataset size and budget, you can use different data labeling methods.
Let’s look at the most common approaches:
1. Programmed Data Labeling
As the name suggests, this method involves custom scripts or automated rules written by data scientists (to label large datasets quickly).
Programmatic labeling is a more technical and scalable approach because it uses functions to automatically produce labels.
The main purpose is to reduce the reliance on manual labor.
Choose this approach if:
- You are dealing with a large dataset.
- You want to speed up the labeling process.
- You prefer automation rather than manual labeling.
2. In-House Data Labeling
In this approach, your internal team of data scientists or annotators handles the labeling work.
This gives you better control over quality, security, as well as the process itself.
But keep in mind that it can be resource-intensive and may not be budget-friendly for small businesses.
3. Outsourcing Data Labeling
Don’t have an in-house team of data scientists? No need to panic.
You can simply get in touch with any outsourcing team to manage the task on your behalf.
Most outsourced teams, such as HiredSupport, have teams of data scientists to complete organized data labeling at a very affordable budget.
Why You Should Outsource Data Labeling Services to HiredSupport
Training an AI model accurately is more challenging than it sounds.
And if you’re struggling with data quality or the accuracy of output, you’re not alone; trust me!
There is a reason why many businesses choose to outsource data labeling and annotation tasks instead of handling them in-house.
At HiredSupport, our team specializes in scalable data annotation.
We help businesses train AI models efficiently…while ensuring high accuracy and standards.
Trusted by over 100+ businesses worldwide, HiredSupport has also earned a 4.9 out of 5 rating on Clutch.
Ready to take your AI project to the next level? Get in touch with our customer service team today to discuss your data labeling requirements.
Summary
With the rising popularity of ML models and ML-based applications, accurate data labeling has also become very important.
I hope by the end of this blog, you have a clear understanding of what data labeling stands for and why it is important for accurate results.
If all this feels overwhelming for you, you can simply outsource your data labeling tasks to HiredSupport; we offer data labeling and annotation services starting from just USD 7!

